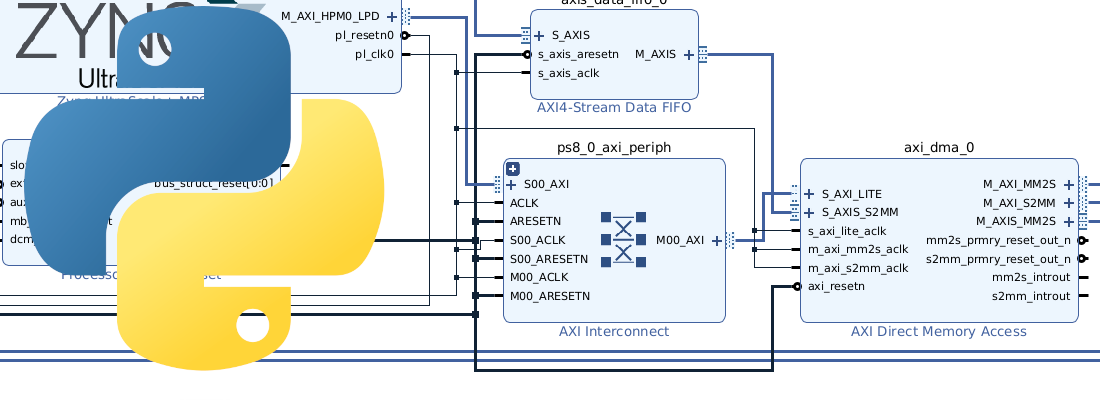
Asymmetric multiprocessing on Zynq MPSOC.

 TE0802
TE0802
On many applications, specially when we talk about signal processing, on the same application there is a mix of real time processing and a non-real time operating system, or on machine learning applications, when we can have a mix of a fast acquisition system, and a powerful operating systems for store and present data, we will need that different processors work together. This applications are perfect for devices like Zynq SOC or Zynq MPSOC.
In case of Zynq SOC there are 2 alternatives, we can use one of the ARM cores to run a Petalinux distribution, and the other one to run a real time bare metal application. Also, the acquisition can be done on PL, for achieve high speeds. The second alternative we have on Zynq, is use both ARM cores to run the Petalinux distribution, and on PL infer a Microblaze processor for real time application.
On Zynq MPSOC, the alternatives are doubled, because there are other processor that we can use, the ARM Cortex R5. This processor is intended to run real time applications, in fact, its name inside Zynq MPSOC platform is RPU (Real-time Processing Unit), unlike the ARM A53 core that is is named APU (Application Processing Unit). On this device, in general, the APU will run a Linux distribution in their 4 cores, and the 2 cores of the RPU will be used to run real time applications, but like in Zynq SOC, we can run bare metal application on one of the cores of the APU, but, that’s not the goal of this processor.

On this post, I will focus on Zynq MPSOC, since the architecture is more complex, and I think is most interesting than Zynq SOC, but the guide can be valid also for Zynq SOC.
As I said, Zynq MPSOC has inside several kind of processor to be used for out purposes. The Application processing unit is a quad/dual ARM cortex A53 where, in general, we will run a Petalinux distribution. This processor has access to its own cache memories, DDR memory through 2×128 interfaces, the OCM through AXI, and this is important, has access to the tighly coupled memories (TCM) of the RPUs though AXI.
The RPU, has access to its TCM memories, the DDR through 1×64 bits interface, ans like the APU, has also access to the OCM memory through AXI interface. Both processors has access to the BRAM on PL through several high performane AXI interfaces.
After this little explanation of the memory accesses of each processor, I will explain you why that is important. When we have a system with multiple processors, and each one is running its own program (baremetal, Petalinux, freertos…), memory has to be segmented to each processor, in other case, the writing process of one processor can destroy the program of the other one, making a crash on the execution. On Zynq MPSOC, each processor has its own memories (cache for APU, and TCM for RPU), and also, there are a shared memory, the DDR, OCM and BRAM. On the example I going to show you, we will run Petalinux on the APU and a baremetal application on the RPU, and also, some data will be shared between APU and RPU.
In this case, Petalinux will use the DDR, and the RPU will allocate its program on its own TCM. TCM are memories inside the RPU cores, due to this can achieve high speeds and low latency. Each RPU core has its own TCM memory, so it to be expected that can share addresses. In the case of we will use both RPU cores as one, TCM memories will allocate in series, so both cores will access to both TCM memories.

For the this hypothetical design, some variables will be shared between APU and RPU, and we can allocate them on DDR, or on the TCM. At this point, we have to keep in mind where these variable will be used, because, in case of the variables will be set on the APU, and used to some algorithm on the RPU, is interesting allocate this variables on the TCM, because they will be used on the RPU, and it has a low latency access to operate with them, but in case of the variables are created on the RPU, and sent to the APU to be used, maybe we prefer allocate the variables on the DDR, because APU has up to 2×128 bit accesses to the DDR, but only 1×64 bits to the TCM.
Summarizing, we have a application, that use a Petalinux distribution running on the APU, and a real-time application running on the RPU. Petalinux will be allocated on the DDR, and the real-time application on the TCM, and we will use the TCM to store shared variables since we have to use them to compute an algorithm on the RPU. Now, how we can do that?
As Petalinux distribution will use all the DDR memory, all options on Petalinux configuration will remain per default. If we want use part of the DDR to run any other application, we need to change the DDR assignation to the Petalinux distribution, for ensure the separation of the applications.
On the RPU side, default configuration execute the application also on DDR, a that can be a problem, so we need to change the allocation of the application by changing the linker file. On our SDK or Vitis project, we will have a file named lscript.ld. When we open this file, the envirment open a editable GUI. By default, we will see that all section are assigned to the DDR memory region, so all the code will be stored on DDR. For execute the code on the TCM, we need to change all assignments to the memory psu_r5_0_atcm_MEM_0. Making this, we will execute the application from ATCM memory.

Notice that each core of the RPU has 2 seperate TCM regions, and, unfortunately, we cannot create a region for both TCM because they are not consecutives. If we need more space that one TCM memory has, we can split the code on the two TCM memories, but 64kB will be enough for most applications.
At this point, we have 2 applications running on different memories, now we can create shared variables. On RPU side, I assume that the application is developed in C, so we have to declarate a global pointer to the address that we want use for store variable.
long *shared_configuration_amplitude = (long*)0x00000000;
long *shared_configuration_ctrl = (long*)0x00000004;
On the APU side, we have to take in count that addressing of TCM from APU is different than RPU addressing. To write on that memory addresses from Petalinux, if we are developing a Python application, we can use the mmap library.
import os
import mmap
import struct
foo = os.open("/dev/mem", os.O_RDWR | os.O_SYNC)
# Create peripheral
data2rpu = mmap.mmap(foo, 0xf, flags=mmap.MAP_SHARED, prot=(mmap.PROT_READ | mmap.PROT_WRITE), offset=0xFFE00000)
data2rpu[0:2] = struct.pack("=H", data2write)
Last, we have to configure the boot. On Zynq MPSOC start up, all applications has to be copied from SD card to the corresponding memory. For configure that, we need to create a .bif file (Boot Image File). On this file we will configure where each application will be executed. This file is created from Vitis/SDK environment (Xilinx > Create boot image), and for each application (RPU application, Petalinux, uboot, fsbl..), we need to assign the device where it will be executed. More information about bif generation can be found on UG1283, or here.
For Zynq SOC, the process is similar, but the options have reduced since there are no RPU.
SOC or MPSOC are devices with a high adaptability, what do this devices useful for any different application. Tho possibilities that we had talk on this post, open doors for, from only one device, manage low latency, and low power processes, up to powerful processes envolving high level communications over a Linux distribution. Thanks for read!